FELLE
Autoregressive Speech Synthesis with Token-Wise
Coarse-to-Fine Flow Matching
Abstract. To advance continuous-valued token modeling and temporal-coherence enforcement, we propose FELLE, an autoregressive model that integrates language modeling with token-wise flow matching. By leveraging the autoregressive nature of language models and the generative efficacy of flow matching, FELLE effectively predicts continuous-valued tokens (mel-spectrograms). For each continuous-valued token, FELLE modifies the general prior distribution in flow matching by incorporating information from the previous step, improving coherence and stability. Furthermore, to enhance synthesis quality, FELLE introduces a coarse-to-fine flow-matching mechanism, generating continuous-valued tokens hierarchically, conditioned on the language model's output. Experimental results demonstrate the potential of incorporating flow-matching techniques in autoregressive mel-spectrogram modeling, leading to significant improvements in TTS generation quality.
Contents
Model Overview
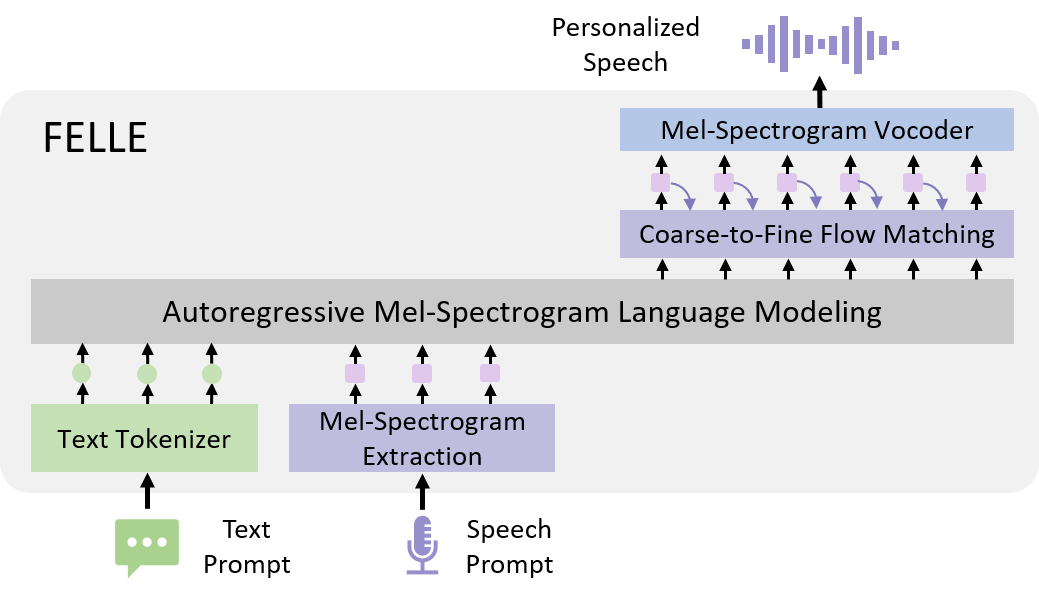
Figure. Overview of FELLE, an autoregressive mel-spectrograms model that generates personalized speech from text and acoustic prompts. At each timestep, the framework relies on the previous mel-spectrogram distribution as a prior, conditioned on the output of the language model, applying a coarse-to-fine flow-matching module to produce refined spectral features.
Zero-Shot Text-to-Speech for Cross-Sentence Task
Samples are from LibriSpeech dataset.
| English Text | Speaker Prompt | MELLE | FELLE |
|---|---|---|---|
| for a long time he had wished to explore the beautiful land of oz in which they lived | |||
| he shall not leave you day or night whether you are working or playing or sleeping | |||
| john taylor who had supported her through college was interested in cotton | |||
| soft heart he said gently to her then to thorkel well let him go thorkel | |||
| and lay me down in thy cold bed and leave my shining lot | |||
| there is no class and no country that has yielded so abjectly before the pressure of physical want as to deny themselves all gratification of this higher or spiritual need | |||
| as to his age and also the name of his master jacob's statement varied somewhat from the advertisement | |||
| horse sense a degree of wisdom that keeps one from betting on the races | |||
| the stop at queenstown the tedious passage up the mersey were things that he noted dimly through his growing impatience | |||
| then he rushed down stairs into the courtyard shouting loudly for his soldiers and threatening to patch everybody in his dominions if the sailorman was not recaptured |
Zero-Shot Text-to-Speech for Continuation Task
Samples are from LibriSpeech dataset.
Note: The first 3 seconds of each speaker prompt audio are used as the reference prompt for synthesis.
| English Text | Speaker Prompt | MELLE | FELLE |
|---|---|---|---|
| milligram roughly 128000 of an ounce | |||
| i get tired of seeing men and horses going up and down up and down | |||
| i will show you what a good job i did and she went to a tall cupboard and threw open the doors | |||
| the utility of consumption as an evidence of wealth is to be classed as a derivative growth | |||
| but philip is honest and he has talent enough if he will stop scribbling to make his way | |||
| i made her for only 20 oars because i thought few men would follow me for i was young 15 years old | |||
| they they excite me in some way and i i can not bear them you must excuse me | |||
| it sounded dull it sounded strange and all the more so because of his main condition which was |
FELLE with Different Parameter Configurations
Samples are from LibriSpeech dataset. We compare FELLE's performance under different NFE (Number of Flow Evolution steps) and CFG (Classifier-Free Guidance) scale settings.
| English Text | NFE=3, CFG=1.6 | NFE=6, CFG=1.6 | NFE=3, CFG=1.0 | NFE=3, CFG=2.2 |
|---|---|---|---|---|
| forthwith all ran to the opening of the tent to see what might be amiss but master will who peeped out 1st needed no more than one glance | ||||
| also a popular contrivance whereby love making may be suspended but not stopped during the picnic season | ||||
| then as if satisfied of their safety the scout left his position and slowly entered the place | ||||
| positively heroic added cresswell avoiding his sister is eyes | ||||
| we want you to help us publish some leading work of luther is for the general american market will you do it | ||||
| but the memory of their exploits has passed away owing to the lapse of time and the extinction of the actors | ||||
| surely it must be because we are in danger of loving each other too well of losing sight of the creator in idolatry of the creature | ||||
| i have not had a chance yet to tell you what a jolly little place i think this is |
Ethics Statement
FELLE is purely a research project. FELLE could synthesize speech that maintains speaker identity and could be used for education, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chat-bot, and so on. While FELLE can speak in a voice like the voice talent, the similarity, and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.
This page is for research demonstration purposes only.